Digging into Data: the research problem
Electronic Enlightenment contains tens of thousands of letters, which should in principle allow us to track the movement of documents, ideas and people across Europe, the Americas and beyond, from the late 17th to the early 19th centuries. Each document is written from some location (or locations) and sent via some route and courier to another location (or locations). This should provide the raw material for an unparalleled insight into the practical operation of historical means of communication and the spread of ideas, political and economic influence, even of literary and personal fashions, at the birth of the modern world.
Incomplete information for analysis
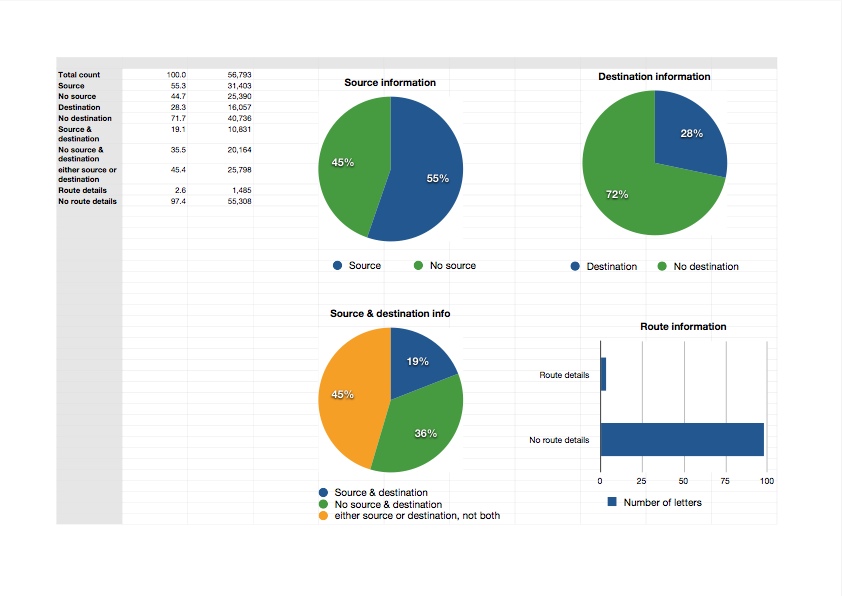
However, the ideal of acquiring precise geographical knowledge of location and transit is not so easily achieved. Many letters have no information regarding the location of writing, transit, or receipt: out of the current corpus of 56,793 documents, only 55% have information on the location of composition, approximately 45% have no information on source, and less than 3% have information on route of travel.
Traditional scholarship's attempt to fill in the blanks
In the past, a scholar may have been able to develop a selective plotting, temporal and spatial, for a few (probably high-profile) individuals — a general lifetime map for Voltaire or David Hume, perhaps. However, such knowledge would always be more like a handful of disparate beads than a necklace: always a more or less random sequence of what should be "graded pearls", missing both the connecting thread and significant intra-sequence beads. Among other limiting factors, our historical scholar could rarely take account of a wide enough spectrum of evidence drawn from the innumerable disparate documents by contemporary figures.
Digital collections and digital analysis takes us forward
This is precisely the sort of opportunity offered by a digital research project like Electronic Enlightenment. By the accumulation of significantly large and continuously growing numbers of documents within the same field-set, and by the application of digital sampling and analysis, we are able to discover more of the missing "pearls" in the necklace, identify their place in the sequence and thereby provide "probability clouds" for the location of still missing "beads".